Michal Paszkiewicz
#1 year of languages - fortran
Like most fools, I have started the year by trying to make some new years resolutions. Aside from the very personal ones you don't want to hear about, I have decided to try to:
- Create a small project in a language I havn't used before every week (and publish a post on it)
- Review my books on my blog, rather than on goodreads
- Review books in a bit more detail
- Make this site look a bit better
So I have now started on the first point! For the first week, I have been learning fortran (by following this tutorial).
How I selected a project
At the end of last year, I received an update from goodreads as to how I had done with my 2016 reading challenge (45 books) - I had not only completed it, but surpassed it (52)! While selecting my new challenge for 2017, I started wondering as to whether my reading speed had increased at all last year. So here was my project - to analyse my goodreads reading data to see if I was getting better at reading.
What I think about fortran
Obviously, I have only spent a week learning fortran in my spare time, so do not expect me to do anything more than state the naive opinions of a novice.
I love the way fortran deals with arrays! It is fantastic - when you apply operations to an array, it does it to every item in it. I also like the fact that fortran has maths functions accessible without loading any library. This is wonderful, since it means I will not have to write "Math" at any point ("Maths" without an "s" always frustrates me). Reading data from a file was also pretty simple for such a low level language. However, I was annoyed that there are no in-built string operators that would, for example, let you split a string by a certain character. Other than that, I really enjoyed learning from the tutorial I was using, which covered everything I needed.
Results
I have published this week's code on github for all to see (it's not too nice). Before running the code, I had assumed that my reading speed would have improved during the reading I had done in 2016 (I had read more that year than ever before). What I didn't expect, was an almost random spread of data. I have tried to split the data into three categories defined by the type of the book. The type of the book should show how difficult the book was to read. I have found that (expectedly) I read fiction the quickest. Non-fiction is a bit slower, but not as slow as the more technical books I read which may require me to complete exercises or re-read passages multiple times. The graph below shows the results with the data split into these categories.
Reading speed (pages/day) vs day of the year (2016)
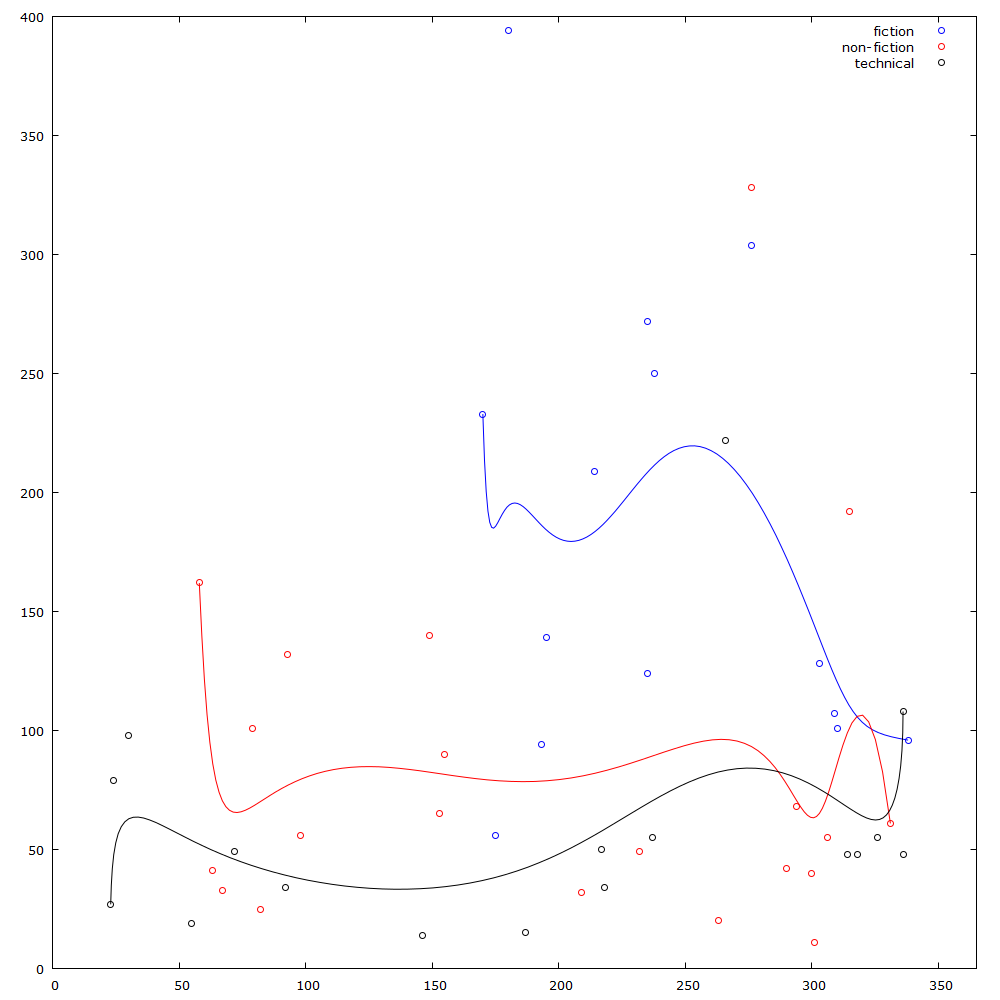
The pretty obvious lack of correlation between the points was quite disappointing to me, so I generated some bezier curves to at least get some nice lines that might show more or less how my reading speed has changed for the various book types throughout the year. These curves seem to suggest that my technical reading speed might have actually improved (although my fiction and non-fiction reading seems to have slumped). The nice thing to see is that the fiction reading (which only started about half-way through the year) seems to give the most sporadic data, with one book approaching almost 400 pages read per day, while other fiction books have been read at under 100 pages a day.
Well, it has been a fun experience and I imagine I might revisit this code at the end of this year to see if a 2-year data span would add any correlation.
published: Sun Jan 08 2017